What should I study?
In the data industry, the amount of tools and processes can be quite fragmented usually coupled with a very steep learning curve and very rapid development, it puts one on a constant learning pedal. A very common question I get asked is:
How do you choose what to study? and how do you stay motivated if things keep changing all the time?
I never really thought much about it until now. To understand where my perspectives are, it is probably beneficial to understand a little bit on my background.
If you are in a hurry, skip to the framework section!
Background
I graduated in late 2013, and in the same year I had an internship during summer break. The internship made me realize that university's education is not sufficient for workplace.
In addition, before I entered university in 2010, I watched this movie 3 Idiots and this quote stuck with me since:
Pursue excellence, and success will follow, pants down!
The idea is to continuously study, to improve and not afraid to be different. After graduation, I began to gobble up materials, trying to improve as fast as I possibly can and always eager to try new things. Sounds good, right?
Result
TLDR - I failed and I was disappointed. I was too eager to master everything which resulted in learning nothing despite putting in immense amount of time. I have made 0 progress.
These are the top 2 most valuable lessons I have learnt:
Lessons Learnt
Change is hard
Key Lesson:
Getting people to change is hard! Always take into account of this as part of your decision making process.

Credits - Check out his other cartoons as well!
Personal Example:
In one of my (early) jobs, I was pretty excited on open source, and was very eager to use R. The existing employees were all familiar with SAS and other various dashboard tools such as Tableau. Getting them to move to R was an uphill task.
In another project I was involved in, I was in-charge of delivering something end to end (alone), I thought it was a good time to try out a new framework and new technologies. The project launch went exceedingly well and I got recognized (quite publicly) for it. The company was talking about it - but after a few months, nobody wanted to go near this project due to the complexity and unfamiliarity ; it turned people off.
What resulted in the end is I kept getting feature requests only I could implement in the organization, and context switching (while being involved in another project) was extremely painful.
That is when I realized, sometimes choosing the tech stack with the team's most common denominator is not always a bad thing. Either that, or get ready to spend hours to up-skill your team and hand-hold them.
Learning is hard
Key Lesson: You are not work ready until you have encountered despair. That is when most people give up. Do not be like most people. This is not just specific to coding, but learning any new skill in general.
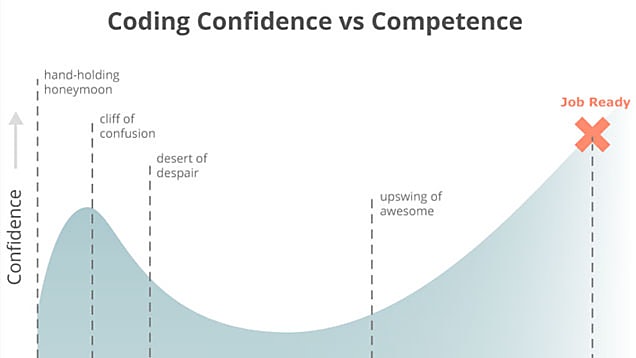
Credits - a good read.
Common mistakes related to this
In the diagram, on the y-axis it says "Confidence". I witnessed quite a handful of fresh graduates or managers who have read "hello world" tutorial(s) or marketing article/jargons and immediately decided that they are now a world expert on that particular subject.
Unless you are a genius, the odds are against you. Why do I say so?
In terms of knowledge, we can split it into 4 different segments.
- What you know you know.
- What you don't know you know.
- What you know you don't know.
- What you don't know you don't know.
When deciding to learn something, most likely you start with (3), and, as you discover more of what you know you don't know, you consequently should also discover more things you don't know you don't know. As a result, the pool of what you know you don't know will (and should) always increase. (Unless you are a genius!  )
)
Moral of the story
Perhaps more apparent in the data industry, choosing what to study has a larger impact and consequence - because it is likely that the team needs to adopt it as the new standard or integrate it to the existing standards.
| Lesson Learnt |
To Avoid it |
| Change is hard |
Understand why you need to change since setbacks will happen in the process of change |
| Learning is hard |
Acknowledge that you will need to endure the pain before you achieve glory |
How can I have a framework that encompasses all of the above?
Framework
I found asking myself this question is really useful:
What pain points I (or the team) encountered last year I want to solve this year?
The tricky part with this framework, is you need to be able to identify your pain points and actively reflect upon them; which might not be a very easy thing to do.
Since the pain already exists, in order to remove or reduce the pain, change is essential, otherwise, the pain remains. Setbacks will probably occur because it is not applicable or assumptions were made. It is important to acknowledge that this will always be part of the discovery process, after all, a collection of mistakes is called experience. Secondly, understand that there will always be a gap between theory and application. Practice is undergoing the "desert of despair" and climbing out of it is where value is created and skill sets are acquired. Nothing will teach you better than practice.
Sometimes it is also good include a goal that is not related to any pain points just for learning purposes but do not spend the majority of your time on it.
Deciding what to learn
To prevent yourself from getting demoralized or burn out, remember this:
“Deciding what not to do is as important as deciding what to do. - Steve Jobs”
Since then, I decided that at any point of time, I should only have 3 things on my plate. Those 3 things should be your highest priorities. If I wanted to add something else, I have to either finish something currently on the plate or drop something.
Using the framework
After identifying and studying your pain points, set the appropriate goals. Think of possible solutions to achieve the goals, and prioritize them into top 3 and constantly iterate them as you discover more.
Below are my personal examples starting from 2016:
2016
Goal:
After trying to master everything, I realize i was chasing hype which resulted in half-baked understanding. I should focus and understand why companies use certain technologies and the "why".
Solution:
- Learn Modeling Intuition (Why use one model over the other?)
- get familiar with Big data stack (Hive, Spark, etc) and the use cases.
- Get familiar with cloud computing and the use cases.
2017
Goal:
I was frustrated being a "Power Point/Dashboard" Data Scientist to someone who is able to deploy models into production.
Solution:
- Get skills in order to find employment in a tech company. (Made the shift in Q4 2017)
- Learn how to build data products.
- Learn Python.
2018
2018 was a very interesting year for me. I was placed in a position in a new product launch.
For that year, I put the company's goals above my own. It was definitely one of the most painful years but highlight of my career so far. Also, being a new joiner there was already plenty of tools and process for me to learn! (E.g It was the first time I had to deal with billion rows and using spark was a necessity instead of a proof of concept.)
If you want to know...
I was in-charge and tasked to develop a credit model for Traveloka's new fintech vertical despite having no experience in credit or putting models into production.
2019
Goal:
While I was successful in launching a machine learning model for credit scoring, there were lots of miscommunication and alignment required. I decided to go back to be an Individual Contributor (IC) and wanted to invest more in my engineering skills.
Solution:
- Develop an end-to-end (sounds like a marketing jargon) application that is integrated with the product funnel to be used in production. This would be a true test of "work ready".
- Learn about data streaming processing (real time streaming instead of batch)
- Learn SQL - to use BigQuery (I was the
Select * Data Scientist and I dataframe-d everything. )
More info
My manager (then VP of Data) was initially against this move, and strongly advised that I should be focusing more on my data science skills and I need to avoid the "lone wolf" mentality since data science is a team sport.
I shared (maybe from his point of view, argued?) with him my reasons for doing so:
- It was mainly driven by my frustrations in 2018 working with multiple cross functional teams to deliver the data product.
- In the worst case scenario, I realized that engineering is not for me and I would have better respect / working relationship with the engineers.
- In the most probable scenario, I can "speak" the engineers' language, hence be able to scope better, relay requirements better and thus make me a more effective IC or manager irregardless.
- In the most ideal scenario, I can do the work myself and all of the above benefits while reducing communication overhead. (communication cost is one of the most expensive!)
He was (still) hesitant but nevertheless, was very supportive and wanted to see what became of it! (Thank you boss - if you're reading this!)
2020
Goal:
As my abilities "scaled" (and being able to see things "end-to-end"), I end up getting multiple (conflicting) requests from many teams. I delivered as many of those as I could, but ended up with a huge technical debt and operational overhead. I want to reduce this going forward.
Solution:
- Build my own website as a way of knowledge repository, both for easy recall and sharing. (It was also a way to put what I have learnt into good use.)
- Write better code, understanding typed python, testing, linting, CI/CD.
- Wanted to know more on experiments and a/b testing (I failed this) - but I learnt a lot more on engineering side, such as tooling, Docker etc.
2021
Goal:
The odds are someone else has encountered my problem and either the cloud platform has a solution for it or there is some open source tool out there. I should spend more time exploring such tools and evaluate them instead of jumping in directly and build my own.
Solution:
- Invest and upscale my cloud knowledge & tooling. (GCP in particular)
- Understand more on data best practices and explore more open source tools. (Tf-X, MLflow, Feature stores?).
- Understand more on experiments & algorithms. (Just for learning)
Reflection so far:
- Understood cloud build, cloud functions, ai platform better.
- Explored more on apache beam, DBT, fastapi, docker compose.
- Did a post on hypothesis testing, and will double down on this.
Will also spend some more time on other algorithms and statistics for the rest of the year.
Goals considered but never made it to the list
I felt that it is important to share the trade offs I have made that were not easy to make. [Steve Jobs' Quote!]. Unfortunately, I have forgotten the tradeoffs made in earlier years.
Here were the trade offs I have made (or things in queue).
- study a new programming language, uncertain whether it should be golang or java
- Try to implement a deep learning use case.
- Study hardware engineering and build something related to IOT.
2022
Gotten a new job, and wish to work more on my data & statistical skills! These are my goals so far, in the order of priority! This time around as I study I hope to translate them to articles in data raccoon! (:
- Spend time on ML, in particular regression, d-trees, and bayesian statistics.
- Get better at data structures.
- Explore the SWE stack and practice data structures.
- Pick up neural network / graphical related technologies.
- Uncertain about other techniques, like time series, ranking, recommendations, computer vision, nlp, reinforcement learning etc.
- Deciding whether to enroll in an online masters or not (?)